
Читайте в Telegram
|
Раньше плохой перевод выдавал себя с первой строки: синтаксис, странные слова, «я есть менеджер проекта». Сейчас нейросеть переводит натурально, текст звучит живо, фразы не режут слух. И именно поэтому ошибки стали опаснее и менее очевидными.
Главная проблема ИИ-перевода в том, что он может звучать отлично и при этом менять смысл. Это особенно заметно в деловой переписке, юридических документах, лендингах, инструкциях, презентациях, маркетинговых текстах, резюме, научных материалах и постах для зарубежной аудитории. Ошибка может быть маленькой: термин обобщен, шутка потерялась, формулировка стала слишком уверенной. Но именно такие мелочи и меняют впечатление.
Мы составили ошибки, которые люди совершают, когда пытаются перевести текст в нейросетях.
Ошибка 1. Переводить слова, а не ситуацию
Один и тот же текст можно перевести пятью способами. Для инвестора, клиента, HR, подписчика, юриста и технической команды это будут разные переводы.
Фраза «we need to move fast» в стартап-презентации звучит как «нам нужно быстрее запуститься». В письме подрядчику — «нам важно уложиться в сроки». В конфликтной переписке — уже «нам нужно быстрее договориться». Слова похожи, а эффект разный.
Нейросети хорошо работают с языком, но им нужен контекст: кто говорит, кому, зачем, в каком канале и какое действие должно произойти после прочтения. Без этого модель выбирает усредненный вариант перевода — грамотный, но слабый.
Исследования машинного перевода постоянно возвращаются к одной и той же проблеме: контекст, идиомы и терминология остаются сложными зонами даже для современных моделей. Обзор в iScience отдельно разбирает трудности контекстно уместного перевода, включая доменную терминологию и выражения, которые нельзя корректно перевести по словам.
Ошибка 2. Доверять чистому переводу
Гладкий перевод часто выглядит убедительнее и удобнее точного. ИИ сглаживает углы: убирает резкость, делает фразы «естественнее», заменяет странную конструкцию на привычную. Для простого текста это помогает, но для профессионального — иногда портит.
В маркетинге может исчезнуть характер бренда. В юридическом тексте может смягчиться обязательство. В инструкции может пропасть ограничение.В научном материале может измениться степень уверенности. В деловой переписке может поменяться дистанция между людьми.
Фраза «we may consider» и «we will consider» отличаются одним модальным глаголом. В русском обе легко превращаются в «мы рассмотрим». Для читателя разница огромная: в первом случае компания оставляет себе пространство для маневра, во втором почти обещает действие.
Поэтому перевод нужно оценивать не только по звучанию. Важно проверять, сохранились ли обязательства, сомнения, осторожность, ирония, степень давления, эмоциональная температура текста.
Ошибка 3. Не давать нейросети словарь
Термины — место, где ИИ чаще всего ошибается. В одном абзаце модель может перевести «pipeline» как «воронка», во втором — как «конвейер», в третьем — как «пайплайн». Все варианты уместны в нужных контекстах, но также могу и создать кашу.
Именно поэтому серьезные переводческие инструменты используют глоссарий. Это пользовательский словарь для стабильного перевода доменной терминологии, названий продуктов и неоднозначных слов. В них можно заранее задать перевод слов и коротких фраз; система учитывает грамматические формы вроде рода, падежа и времени, если язык это поддерживает.
Запомните: перед переводом нужно дать нейросети мини-словарь. Названия продукта, роли, функции, тарифы, юридические термины, аббревиатуры, сленг команды, слова, которые оставляем на английском.
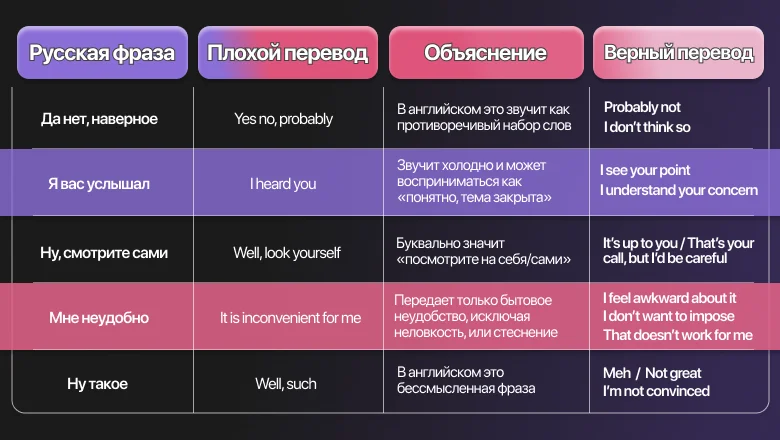
Ошибка 4. Переводить идиомы буквально или слишком метафорично
Идиомы, шутки и культурные фразы — зона, где нейросеть мечется среди двух огней. Первый — буквальный перевод, когда понятно, что имелось в виду, но на языке перевода люди так не говорят. Второй — творческая адаптация, когда модель заменяет выражение на похожее по смыслу, но меняет тон или даже отношение автора.
Например, английское «low-hanging fruit» можно перевести как «простые возможности», «быстрые победы», «очевидные точки роста», «низко висящие плоды». Последний вариант смешной, первый безопасный, третий звучит по-деловому, второй — просто странно. Единственно правильного ответа нет — есть ответ под аудиторию.
Работы по идиоматическому переводу показывают, что даже сильным LLM сложно одновременно сохранить смысл, стиль и культурный оттенок выражения. Исследователи предлагают отдельно учитывать значение идиомы и искать соответствие в целевом языке, а не переводить ее как обычную фразу.
Ошибка 5. Сохранять исходный порядок мыслей
Да, хороший перевод иногда требует перестановки. Для английского текста длинная цепочка уточнений перед главным смыслом — в пределах нормы. Однако русский читатель быстрее устает от такой конструкции. Русский деловой текст часто требует более прямой логики. В обратную сторону работает так же: русский текст с резким вступлением может выглядеть поверхностным на английском.
Профессиональный перевод решает не только лингвистическую задачу. Он пересобирает путь мысли: где-то меняет порядок фраз, дробит абзац, переносит причину вперед, убирает повтор, который в одном языке звучит нормально, а в другом — мешает.
ИИ может так сделать, но ему нужно разрешение: адаптируй структуру под носителя языка, сохрани смысл, переставь предложения, если так будет естественнее.
Ошибка 6. Не различать перевод и локализацию
Перевод отвечает на вопрос: «Как это сказать на другом языке?» Локализация отвечает на вопрос: «Как это должно сработать у другой аудитории?».
Например, для интерфейса это длина кнопки, привычные формулировки, формат даты и валюты. Для лендинга — аргументы, страхи, социальные доказательства. Для письма — тон, дистанция, степень прямоты. Для презентации — логика убеждения. Для соцсетей — ритм, юмор, узнаваемые культурные маркеры.
Если перевести русский рекламный текст на английский буквально, он будет звучать слишком напористо. Если перевести английский лендинг на русский без адаптации, он может выглядеть пустословным: много «empower», «unlock», «seamless», «transform» — мало конкретики.
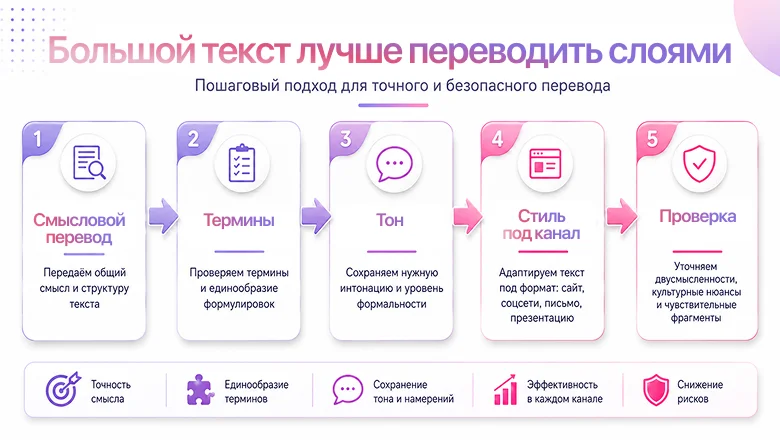
Ошибка 7. Переводить весь документ одним заходом
Если бросить в модель 20 страниц и попросить «переведи хорошо», она может справиться с объемом, но потерять консистентность. Это особенно заметно в презентациях, инструкциях, коммерческих предложениях, брендовых текстах и документах для команды. Там важна не только точность каждой фразы, но и единая система: как называем продукт, как обращаемся к читателю, какие термины оставляем, какие переводим, какой стиль держим.
Нейросети Google отдельно продвигают Translation LLM для сложных переводческих задач и указывает, что модели показывают более высокие MetricX и COMET scores на трудных workloads по сравнению с другими переводческими сервисами. Но даже продвинутые модели лучше работают, когда задача разделена на понятные операции: перевод, терминология, стиль, проверка.
Ошибка 8. Не проверять степень уверенности
Допустим, в исходнике автор пишет: «может привести», «вероятно связано», «по предварительным данным», «в отдельных случаях», «имеет тенденцию». После перевода это превращается в «приводит», «связано», «данные показывают», «обычно», «вызывает». Для медицины, финансов, науки, юриспруденции и публичных заявлений — опасно.
Отдельные исследователи и профессиональные организации уже обсуждают переводческие ошибки как часть AI safety, потому что в высокорисковых сценариях неверный перевод может повлиять на юридические, медицинские, миграционные и другие серьезные решения. Поэтому после перевода стоит искать места, где изменилась сила утверждения.
Чтобы перевести текст в нейросетях качественно, часто нужно попробовать не один инструмент. Одна модель лучше справляется с деловым стилем, другая — с терминологией. В SpeShu.AI можно работать с разными нейросетями в одном окне: 300+ моделей для текста, фото, видео, кода и рабочих задач. Все инструменты доступны по одной подписке, которая работает без VPN. Оплатить подписку можно любой российской картой.
Это очень удобно, когда перевод — часть рабочего процесса: локализовать лендинг, адаптировать презентацию, перевести инструкцию, письмо клиенту, пост, договор, интерфейс или коммерческое предложение. Можно быстро сравнить варианты, проверить тон, собрать глоссарий, доработать стиль и не прыгать между отдельными сервисами.







